Highlights
Traditional recorded lectures are fundamentally passive: when students encounter confusion, they must leave the video to search for clarification. We introduce ALIVE (Avatar-Lecture Interactive Video Engine), a fully local, privacy-preserving system that transforms lecture videos into real-time, content-aware interactive learning environments. ALIVE tightly integrates timestamp-aligned retrieval, locally hosted large language models, and neural talking-head avatar synthesis to enable grounded explanations exactly at the moment of confusion.
Key Achievements:
- 🎯 Content-Aware Retrieval: Combines semantic similarity with timestamp alignment to retrieve lecture segments near the paused moment
- 🔒 Fully Local Pipeline: ASR, retrieval, LLM inference, TTS, and avatar synthesis run entirely on local hardware
- ⚡ Low Retrieval Latency: Embedding + FAISS search completes in <100 ms
- 🧠 Grounded LLM Responses: Llama-based model generates lecture-aligned answers in ~1–2 seconds
- 🎭 Avatar-Delivered Explanations: SadTalker-based neural talking-head synthesis with segmented rendering
- 📊 System-Level Evaluation: Functional grounding validation, latency profiling, and ablation analysis
🏗️ System Architecture Overview
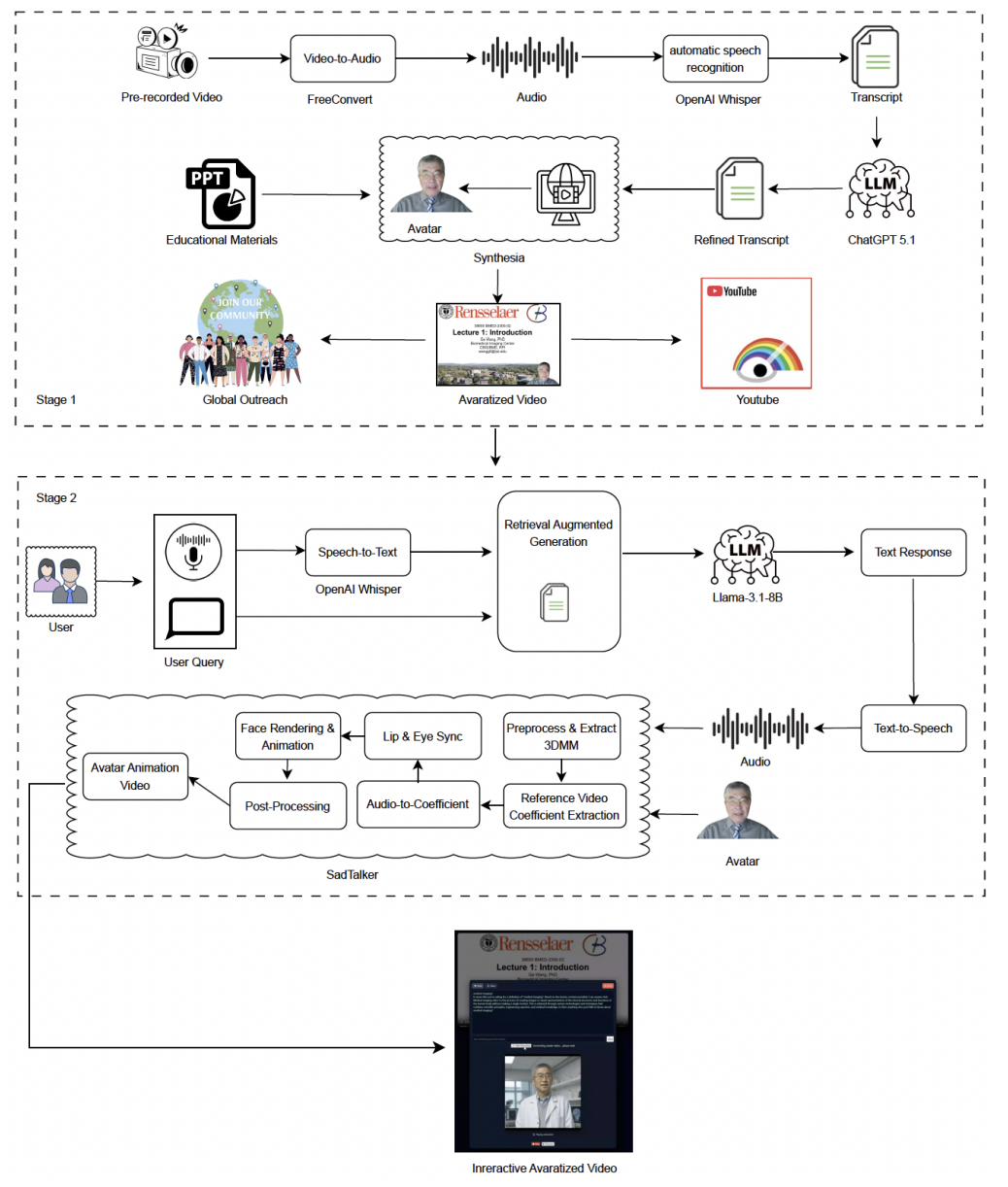
Figure: ALIVE System Overview (adapted from Fig. 1 in the paper). ALIVE consists of three tightly integrated stages: (1) Offline lecture preparation (ASR → transcript refinement → segmentation → embedding index), (2) Pause-triggered content-aware retrieval and LLM reasoning, and (3) Segmented avatar-delivered response generation using offline TTS and SadTalker. All modules operate locally, forming a privacy-preserving multimodal pipeline.
🎯 Motivation & Educational Impact
Recorded lectures provide flexibility but lack real-time clarification. When confusion arises, students must interrupt learning continuity and search externally. This problem is particularly severe in technical domains such as medical imaging, where reasoning depends on physics, reconstruction algorithms, and mathematical modeling.
🔍 Core Challenges Addressed:
- ⏸️ Passive Learning: No built-in clarification mechanism during playback
- ❌ Context Loss: Generic chatbots are unaware of lecture timeline
- 🔐 Privacy Constraints: Many AI systems rely on cloud APIs
- 🎭 Disconnected Presentation: Chat responses break instructor continuity
- ⚡ Latency Issues: Avatar synthesis can introduce startup delay
Innovation: ALIVE anchors all interaction around the lecture timeline using timestamp-sensitive retrieval and provides explanations either as grounded text or instructor-style avatar responses — without leaving the video context.
📊 Offline Lecture Preparation Pipeline
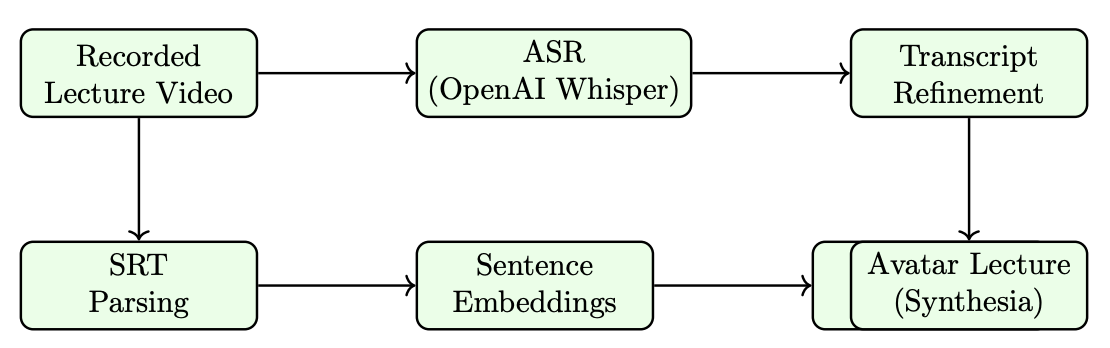
Figure: Offline Lecture Preparation (Fig. 2). Lecture audio is transcribed using Whisper, refined via LLM, segmented (~20s units), embedded using SentenceTransformers, and indexed with FAISS. The result is a timestamp-aligned retrieval store enabling semantic + temporal search.
🔧 Key Components:
- Local Whisper ASR with fine-grained timestamps
- Transcript refinement for grammatical coherence
- Segment merging (~20s) for semantic consistency
- Sentence-level embeddings
- FAISS inner-product index
⏸️ Pause-Triggered Content-Aware Retrieval
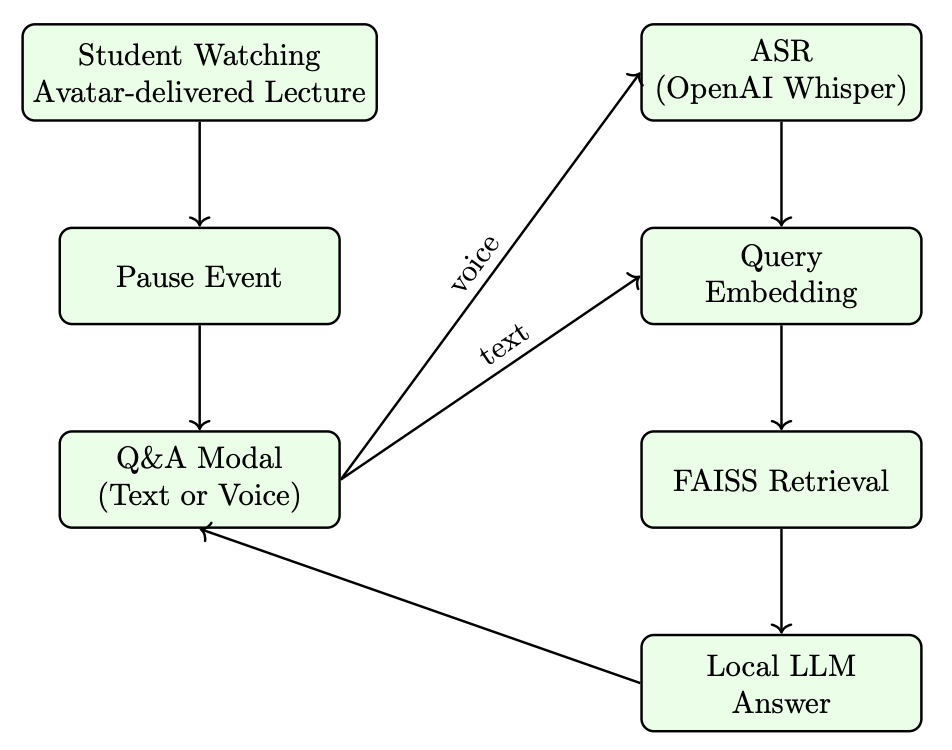
Figure: Content-Aware QA Workflow (Fig. 3). When a student pauses the lecture, ALIVE retrieves segments using a temporally adjusted similarity score:
d̃ᵢ = dᵢ − λ | (sᵢ + eᵢ)/2 − t | / 60
where semantic similarity is penalized by temporal distance from the paused timestamp.
🎭 Segmented Avatar Response Generation
Figure: Segmented Avatar Synthesis (Fig. 4). LLM-generated explanations are converted to speech via offline TTS, then rendered as talking-head videos using SadTalker. Long responses are split into sentence-level segments with progressive preloading.
⚡ Latency Mitigation Strategy:
- First segment rendered quickly
- Remaining segments generated asynchronously
- Segment i plays while segment i+2 renders
- Automatic cleanup of temporary files
📈 Performance Evaluation
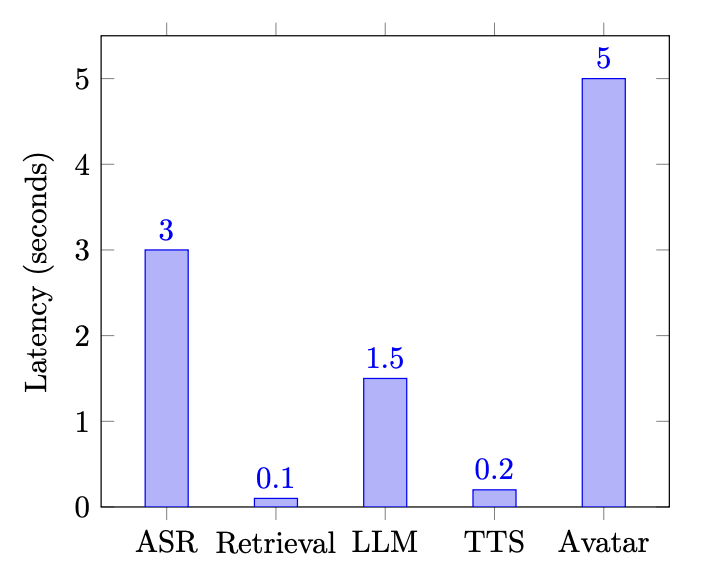
| Component | Observed Latency |
|---|---|
| Whisper ASR (5–10s query) | ~2–4 seconds |
| Embedding + FAISS Retrieval | <100 ms |
| LLM Inference | ~1–2 seconds |
| TTS | <0.2 seconds |
| Avatar Synthesis (per segment) | ~3–6 seconds |
🧪 Ablation Analysis
- Without Timestamp Alignment: Reduced contextual consistency for ambiguous queries
- Without Segmented Synthesis: Increased startup delay and worse perceived responsiveness
🚀 Key Contributions
- First fully local, timestamp-aware interactive lecture engine
- Semantic + temporal retrieval for lecture-grounded QA
- Segmented avatar synthesis with progressive preloading
- End-to-end privacy-preserving multimodal pipeline
- System-level evaluation including latency profiling and grounding validation
🎯 Research Significance
ALIVE demonstrates that modern multimodal AI components — retrieval-augmented LLMs, speech recognition, and neural avatar synthesis — can be composed into a unified, fully local educational system that enhances recorded lectures without compromising privacy. By anchoring interaction to the lecture timeline, ALIVE transforms passive video viewing into responsive, context-aware learning.
📝 Citation
If you find ALIVE useful in your research, please consider citing:
@article{zabirul2025alive,
title={ALIVE: An Avatar-Lecture Interactive Video Engine with Content-Aware Retrieval for Real-Time Interaction},
author={Zabirul Islam, Md and Motaleb Hossen Manik, Md and Wang, Ge},
journal={arXiv e-prints},
pages={arXiv--2512},
year={2025}
}
📖 Paper:
arXiv:2506.05360 (2025)
SlideChain: Semantic Provenance for Lecture Understanding via Blockchain Registration
Highlights
Modern vision–language models (VLMs) are increasingly used to interpret educational slides, but their extracted semantics (concepts and relational triples) can be inconsistent across models and hard to audit over time. We introduce SlideChain, a blockchain-backed provenance framework that anchors cryptographic commitments (Keccak-256 hashes) of per-slide semantic provenance records on an EVM-compatible blockchain, enabling tamper-evident verification, deterministic reproducibility checks, and long-term auditability for multimodal educational pipelines.
Key Achievements:
- 🧾 Slide-level Semantic Provenance: Unified per-slide JSON schema storing concepts, triples, evidence, and metadata across models
- 🔗 Blockchain-backed Integrity: Stores only Keccak-256 commitments on-chain (semantics off-chain) for scalable verification
- 📚 Real Educational Dataset: 1,117 medical imaging lecture slides from 23 university lectures (SlideChain Slides Dataset)
- 🤖 Multi-model Extraction: Analysis over four VLMs: InternVL3–14B, Qwen2–VL–7B, Qwen3–VL–4B, LLaVA-OneVision
- 📉 Reveals Semantic Disagreement: Modest concept overlap and often near-zero triple overlap across model pairs (Jaccard analysis)
- ⛽ Predictable On-chain Cost: Registration gas per slide clusters tightly around ≈231,430 gas (near-constant per registration)
- ⚡ Stable Throughput: Batch registration throughput ≈ 1.0009 slides/sec (1117 slides over 1116 seconds)
- 🛡️ Tamper Detection: 100% detection of synthetic corruption on a tested subset of 20 provenance files
- ✅ Deterministic Reproducibility: Two independent full pipeline runs produced Jaccard = 1.0 for concepts and triples for every model–slide pair
🏗️ System Architecture Overview
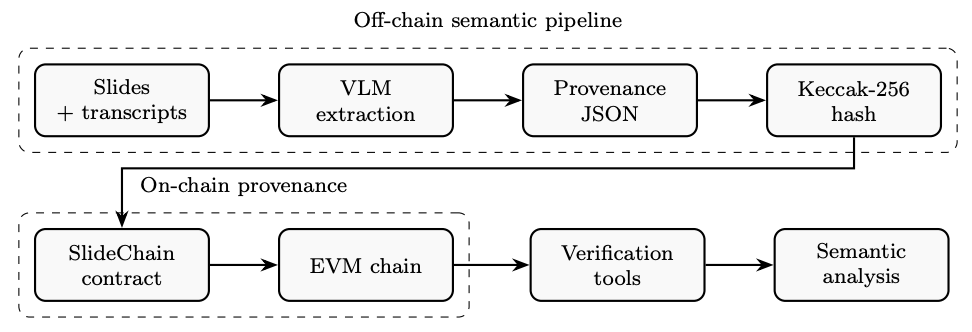
Figure 1: Three-layer SlideChain workflow. Layer 1 (off-chain): slides + transcript snippets are processed by multiple VLMs to extract concepts and relational triples, producing a canonical provenance JSON per slide. Layer 2 (on-chain): a lightweight EVM smart contract stores only the Keccak-256 hash of that JSON (plus optional URI and timestamp). Layer 3: verification tools recompute hashes to detect tampering and support long-term auditing and semantic drift analysis.
🎯 Motivation & Trust Problem
VLM outputs on scientific slides can vary across model families, inference settings, and environments. In STEM education, that instability is risky: missing or spurious concepts, and especially unreliable relational triples, can distort meaning. SlideChain does not try to “fix” the semantics. Instead, it makes semantic outputs verifiable, comparable, and auditable across time and across models by anchoring slide-level semantic records to a tamper-evident ledger.
🔍 Core Challenges Addressed:
- 🧠 Semantic Instability: different models extract different concept sets from the same slide
- 🔗 Fragile Relational Grounding: triple extraction is sparse and often disagrees across models
- 🧾 No Semantic Audit Trail: without commitments, semantic records can be silently overwritten
- ⏳ Long-term Drift: as models/prompts/pipelines evolve, prior semantics become hard to reproduce and verify
- ✅ Need for Independent Verification: provenance should not require trusting a single repository owner or logging service
Innovation: SlideChain anchors the semantic outputs themselves (concepts + triples + evidence/metadata) via on-chain commitments, enabling third-party verification, immutable timestamps, and guaranteed detection of post hoc changes.
📊 Dataset & Models
SlideChain evaluates semantic extraction on real instructional material: the SlideChain Slides Dataset, a curated set of 1,117 high-resolution slides spanning 23 university lectures in medical imaging. Slides include equations, diagrams, imaging geometries, workflows, and dense technical layouts, making them a challenging testbed for VLM slide understanding.
🤖 Vision–Language Models Used:
- InternVL3–14B: dense concept extraction; richest semantic footprint
- Qwen2–VL–7B: strong general multimodal reasoning; diverse concepts
- Qwen3–VL–4B: smaller, more conservative semantic footprint
- LLaVA-OneVision (Qwen2–7B backbone): moderate concepts, consistently low triple production
🧾 Provenance Record (What Gets Hashed)
Each slide produces a canonical provenance JSON containing normalized concept and triple sets for all four models, plus evidence and metadata. Keys are serialized in sorted order before hashing to ensure platform-invariant commitments. The smart contract stores only the hash and optional URI, keeping full semantics off-chain for scalability.
{ "lecture": "Lecture k", "slide_id": n, "models": { "InternVL3-14B": { "concepts": [...], "triples": [...], "evidence": [...], "raw_output": "..." }, "Qwen2-VL-7B": { "concepts": [...], "triples": [...], "evidence": [...], "raw_output": "..." }, "Qwen3-VL-4B": { "concepts": [...], "triples": [...], "evidence": [...], "raw_output": "..." }, "LLaVA-OneVision": { "concepts": [...], "triples": [...], "evidence": [...], "raw_output": "..." } }, "paths": { "image": "...", "text": "...", "json": "..." }, "metadata": { "timestamp": "...", "source": "...", "hash_input_format": "sorted-keys-json" } }
📉 Semantic Disagreement & Cross-Model Similarity
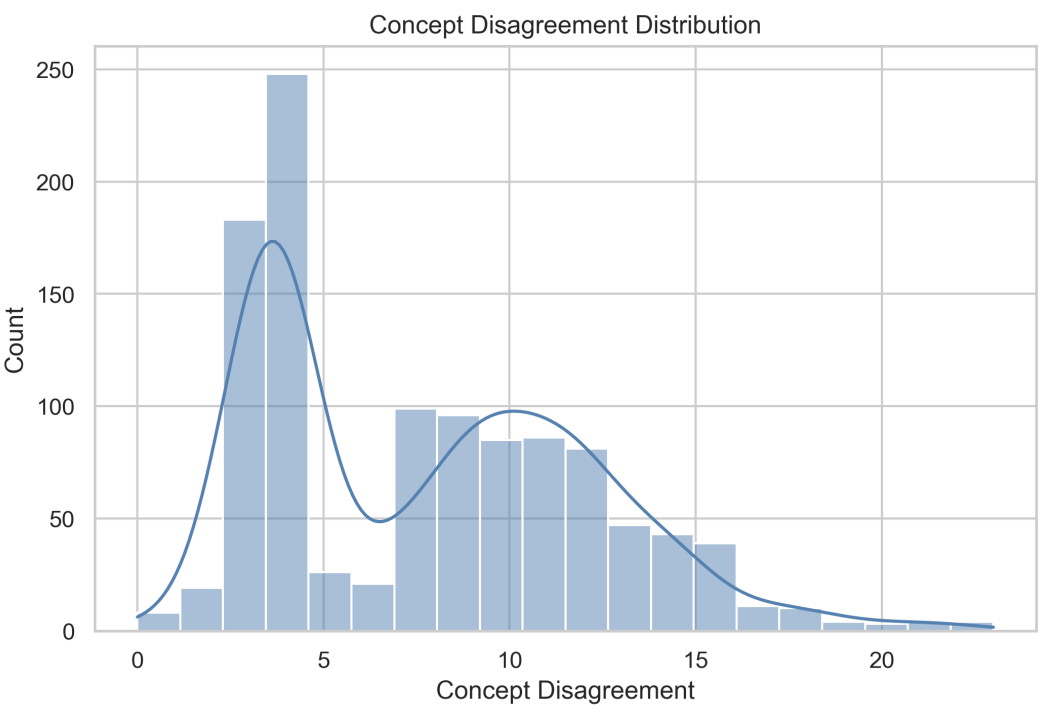
Figure 2: Concept disagreement distribution. Across 1,117 slides, the union of concepts extracted by four VLMs varies widely per slide, showing that different models often propose substantially different semantic “coverage” even under the same input.
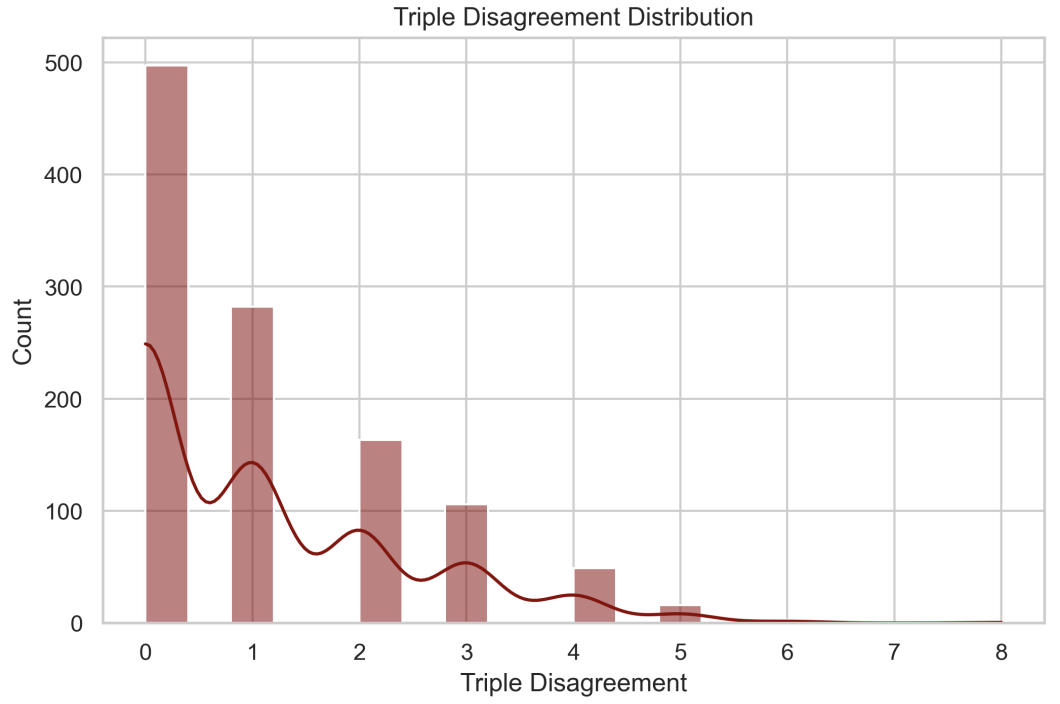
Figure 3: Triple disagreement distribution. Relational triples are overall sparse, but still highly inconsistent: many triples proposed by one model do not appear in others, highlighting fragility of relational grounding on technical slides.
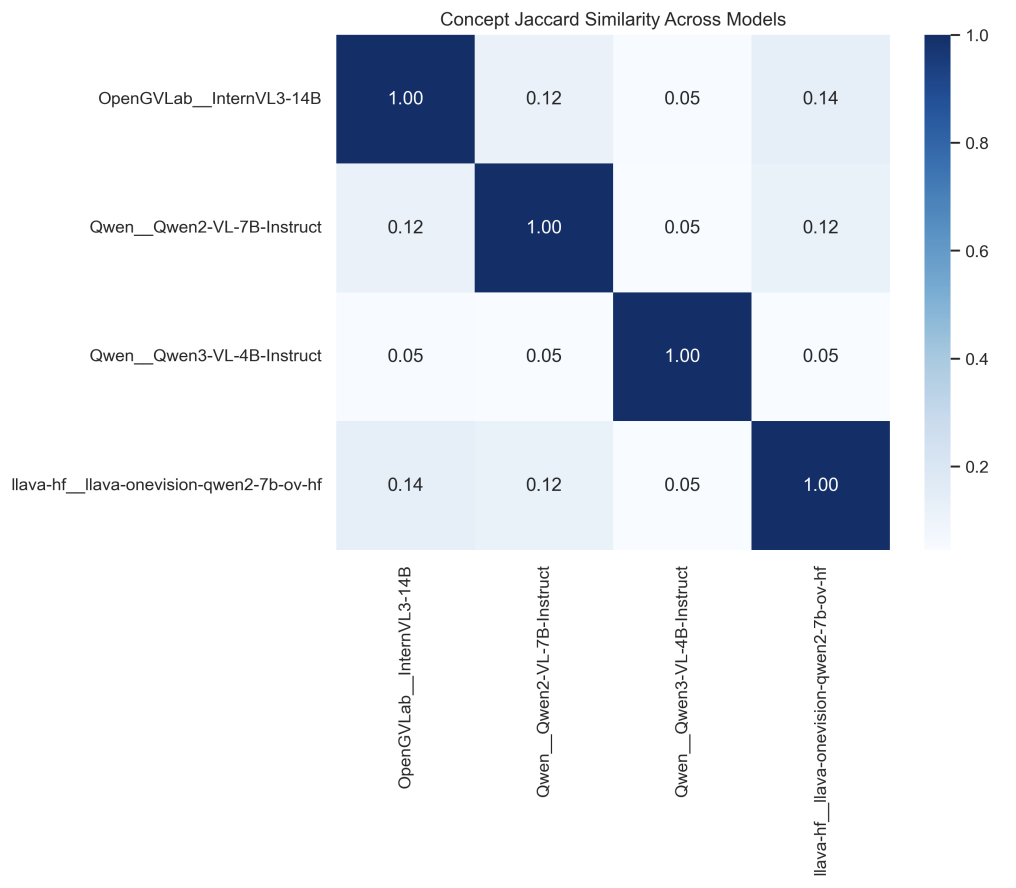
Figure 6: Pairwise concept Jaccard similarity across models. Cross-model agreement is consistently modest, indicating that “high-level slide meaning” varies across architectures and training regimes even when inputs are identical.
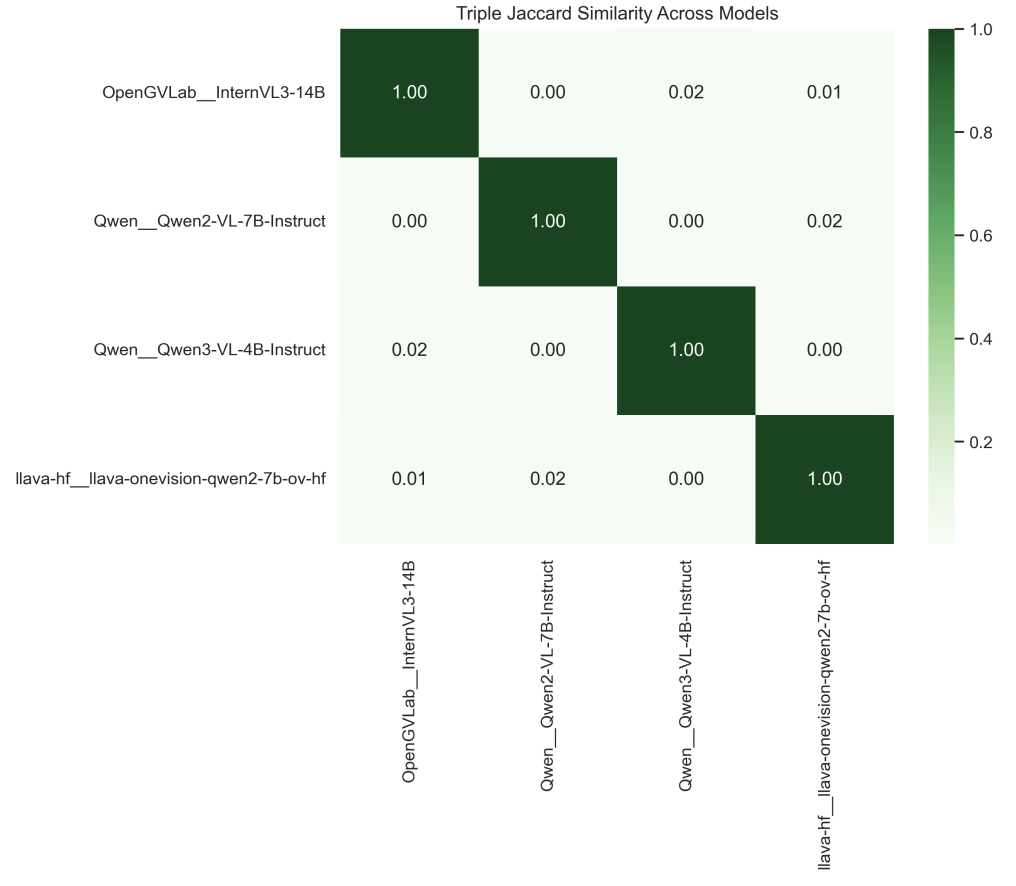
Figure 7: Pairwise triple Jaccard similarity across models. Triple overlap is near zero for several model pairs, reinforcing that relational extraction on dense STEM slides remains brittle and model-dependent.
📚 Lecture-Level Variability & Stability Categories
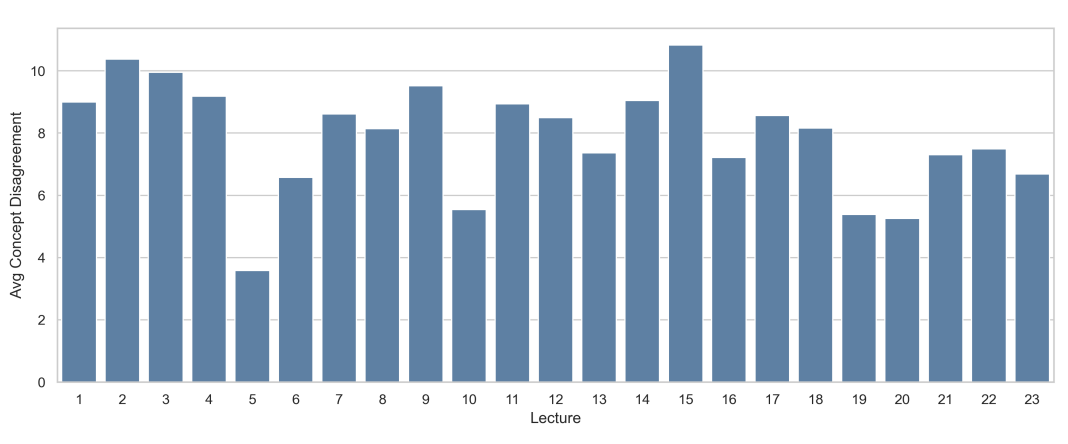
Figure 8: Average concept disagreement per lecture. Disagreement is not uniform: lectures with dense diagrams, reconstruction pipelines, or symbol-heavy content show higher variability.
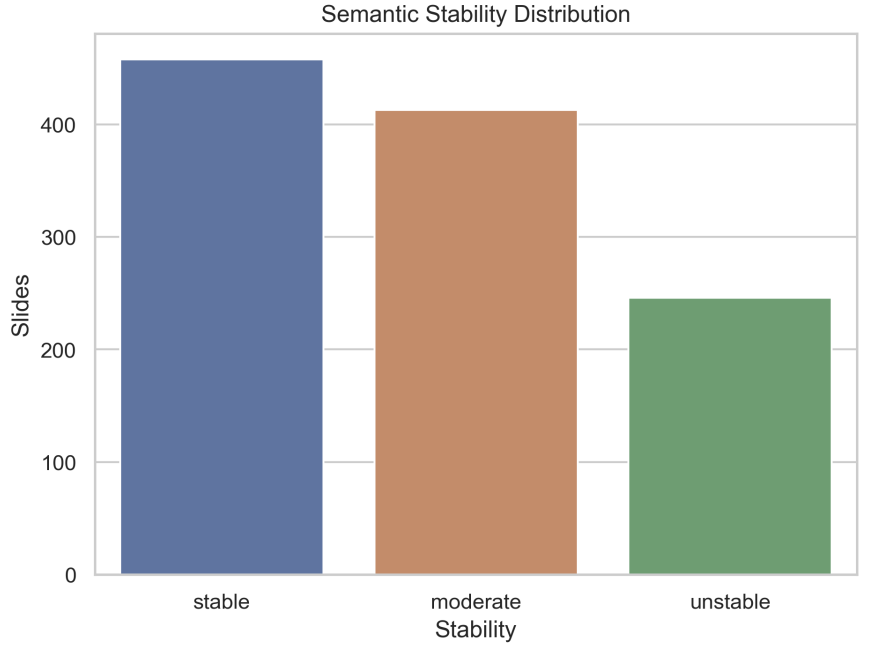
Figure 10: Stability category distribution. Slides are classified into stable, moderate, and unstable bins using concept-disagreement percentiles. A large fraction fall into moderate/unstable ranges, motivating provenance-aware, uncertainty-aware downstream use.
🧪 Single-Model vs. Multi-Model Coverage
To quantify what is missed when relying on a single VLM, the paper compares InternVL3 (as a strong single-model baseline) against the union of all four models. Reported distributions show substantial coverage loss under single-model provenance: concept coverage loss mean 0.62 (median 0.67) and triple coverage loss mean 0.40 (median 0.56).
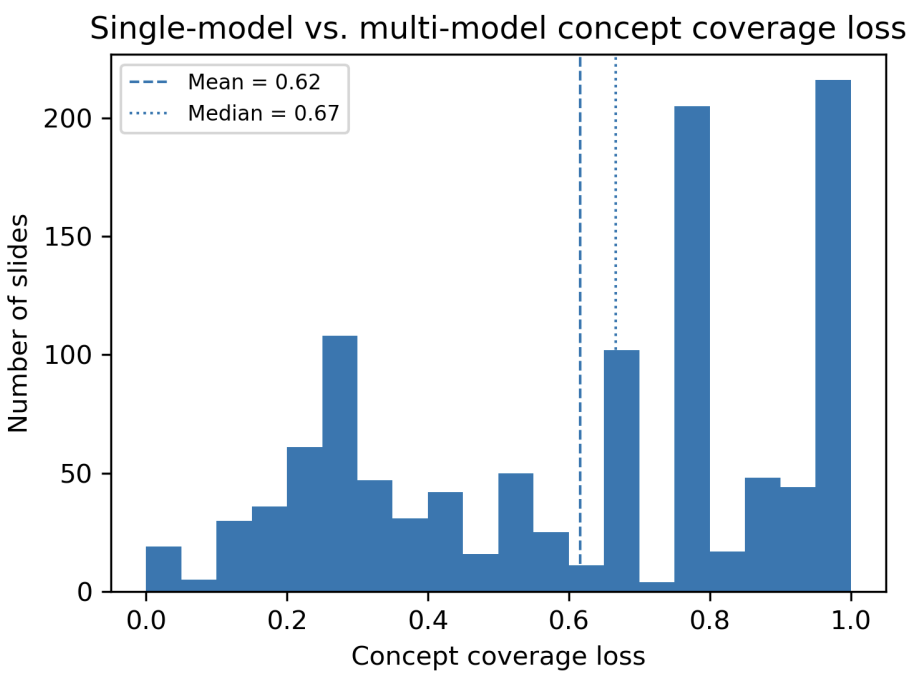
Figure 11: Concept coverage loss. Values close to 1 indicate the single-model baseline misses most concepts present in the multi-model union.
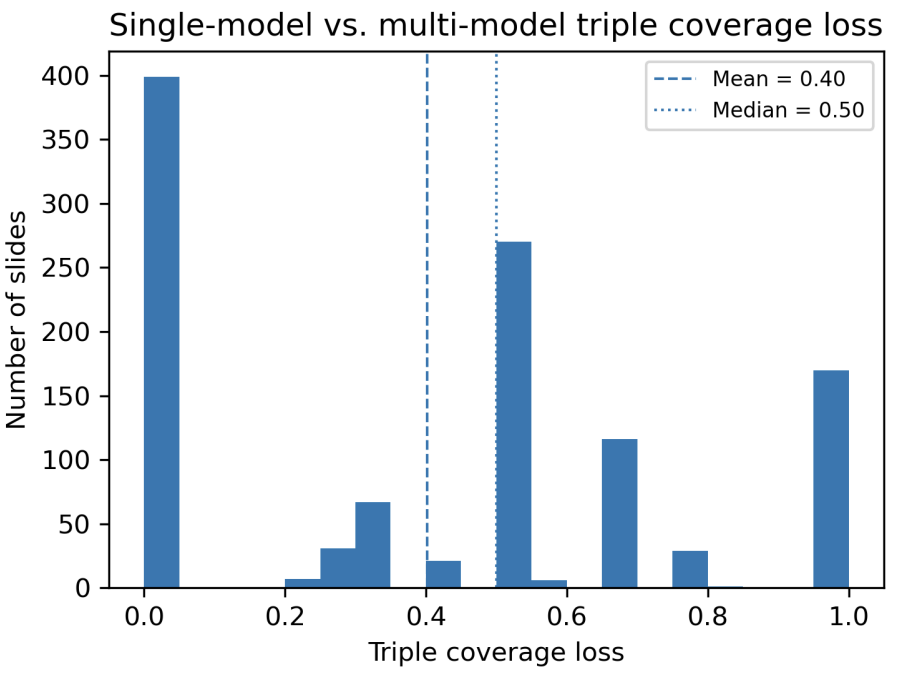
Figure 12: Triple coverage loss. Many slides exhibit partial or complete loss of relational semantics when relying on only one model.
⛓️ Blockchain Setup & Registration Procedure
SlideChain deploys a lightweight Solidity smart contract on a deterministic local Hardhat EVM chain, registering one transaction per slide. Each registration stores (lectureId, slideId) → (hash, optional URI, timestamp, registrant), and rejects duplicates to keep provenance immutable.
🖥️ Experimental Environment (Tables 1–3)
| Hardware (Table 1) | Details |
|---|---|
| GPUs | 4 × NVIDIA RTX A5000 (24 GB VRAM each) |
| CPU | Intel Xeon-class processor |
| System RAM | 256 GB |
| CUDA | 12.1 |
| Storage | Local SSD (blockchain + provenance artifacts) |
| Software (Table 2) | Version / Notes |
|---|---|
| Python | 3.10 |
| PyTorch | 2.2 (CUDA 12.1) |
| Transformers | HuggingFace implementations for all VLMs |
| Scientific Stack | NumPy, Pandas, Matplotlib, Seaborn |
| Node.js | v22.10.0 |
| Hardhat | v3.0.17 |
| Solidity Compiler | 0.8.20 |
| OS | Windows 11 |
| Hardhat Chain Config (Table 3) | Setting |
|---|---|
| RPC | http://127.0.0.1:8545 |
| Accounts | 20 deterministic pre-funded accounts |
| Gas Model | EIP-1559 base fee with deterministic tip |
| Block Policy | One block per transaction (zero-delay mining) |
📈 Blockchain Performance & Cost
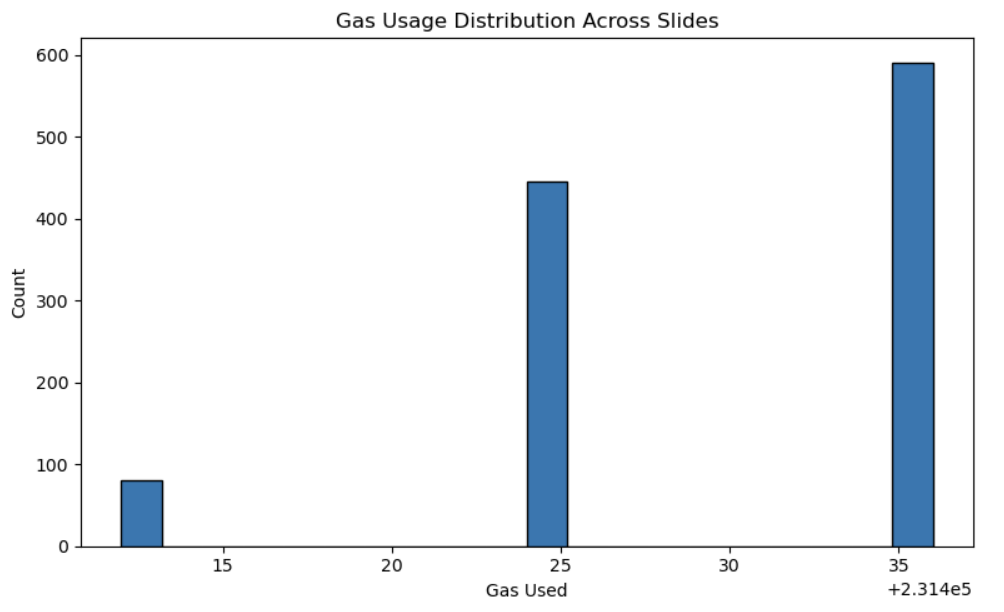
Figure 13: Gas usage distribution across all 1,117 registrations. Gas usage clusters tightly around ≈231,430 gas per slide, reflecting constant-time contract behavior.
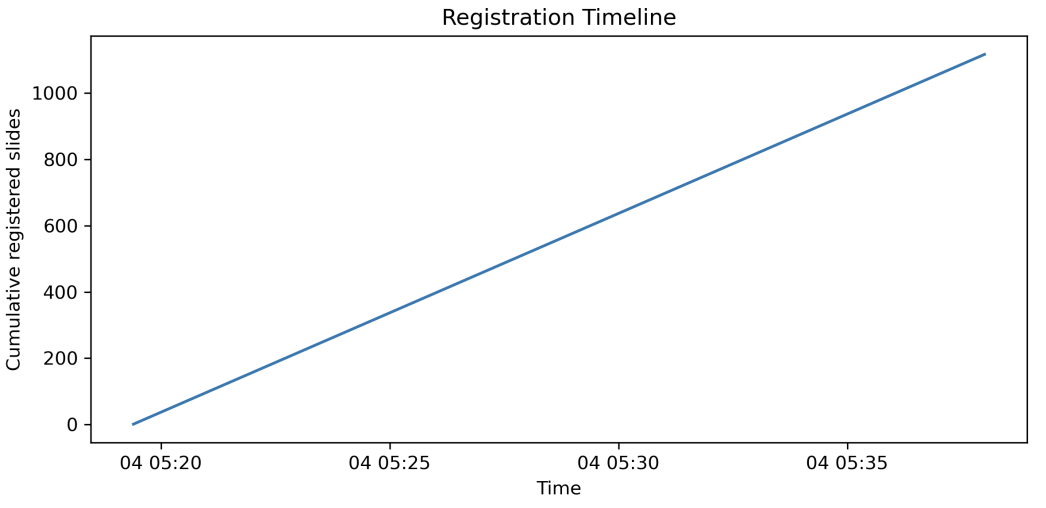
Figure 20: Registration timeline. With Hardhat mining one block per transaction, registration proceeds at a stable throughput of about 1.0009 slides/sec.
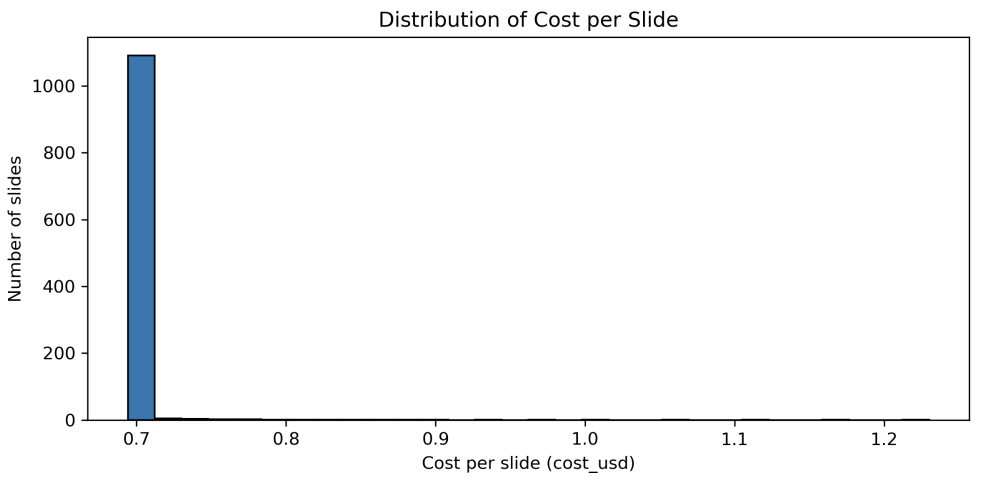
Figure 21: Distribution of per-slide registration cost (USD). Using the paper’s reference assumptions (including $3000/ETH), an Ethereum-like L1 cost model yields per-slide costs roughly in the range $0.69–$1.23, totaling about $780 for 1,117 slides.
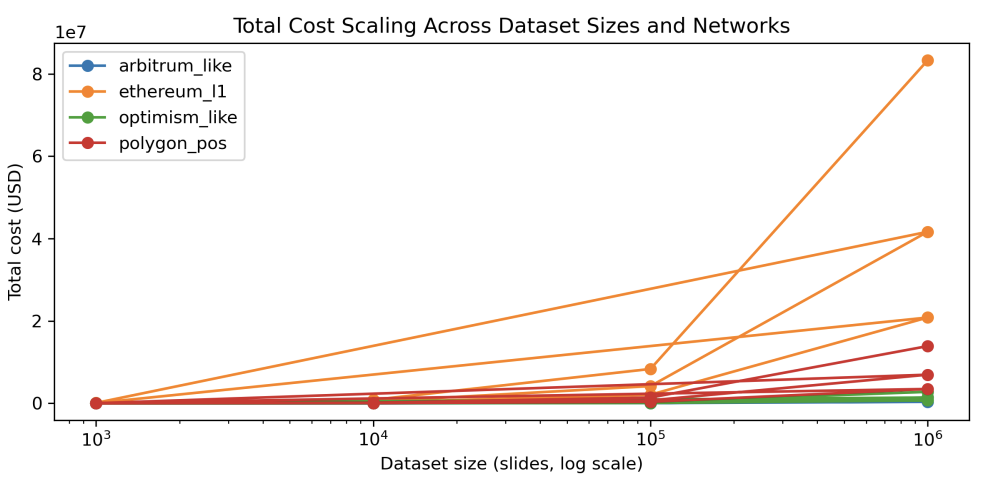
Figure 24: Projected registration costs across networks. Because gas per slide is near-constant, total cost scales linearly with dataset size; L2/sidechain environments reduce costs by one to two orders of magnitude compared to L1.
🛡️ Integrity: Time Gaps, Tamper Detection, Reproducibility
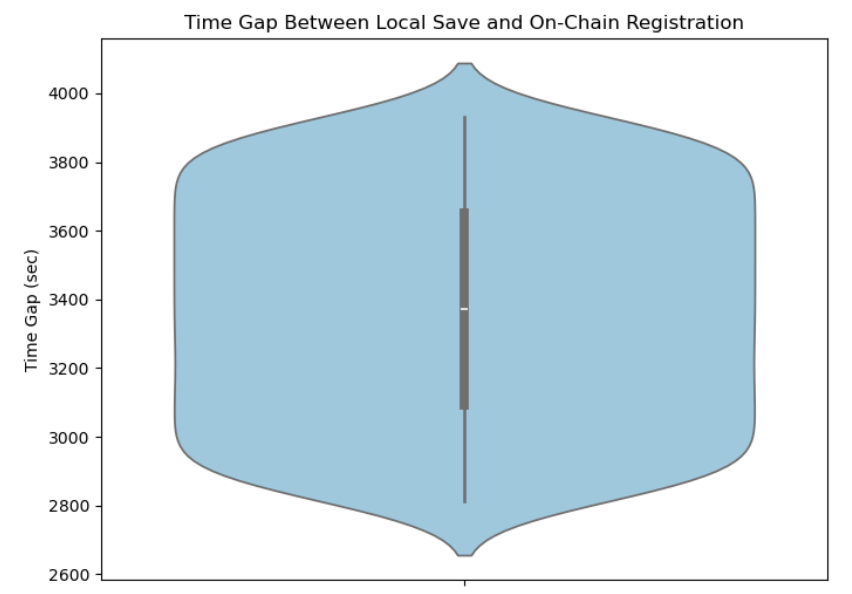
Figure 25: Time gap between local provenance creation and on-chain registration. The distribution is narrow and concentrated (centered around ~3300 seconds in the reported experiment), supporting consistent chronological ordering under the deterministic batch registration procedure.
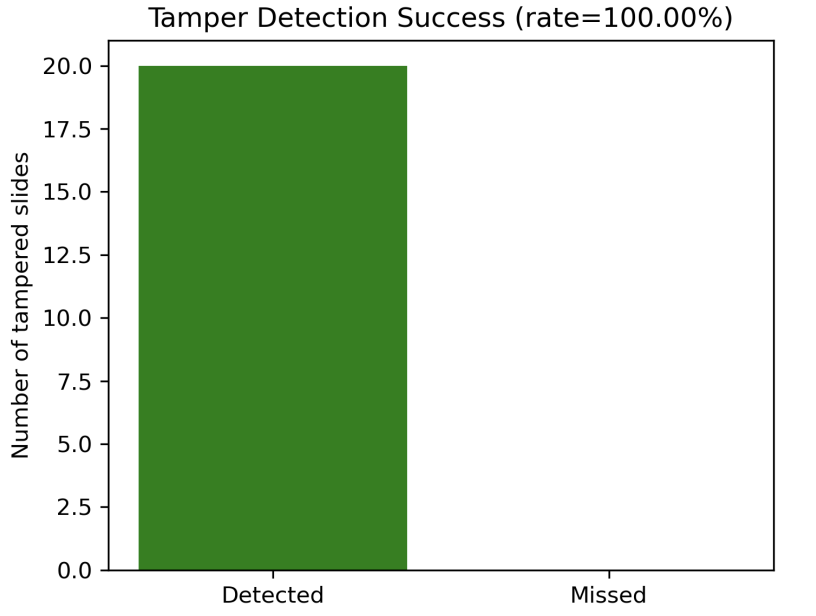
Figure 26: Tamper detection performance. Controlled corruption on a randomly selected subset of 20 provenance files was detected with 100% accuracy, because any change alters the Keccak-256 hash.
- Reproducibility across runs: Two independent full executions produced identical concept and triple sets for every model–slide pair (Jaccard = 1.0 throughout).
- What this enables: Any future mismatch against the on-chain commitment is strong evidence of semantic drift due to model/prompt/pipeline changes or unauthorized edits.
📌 Why Blockchain (vs Git/DVC/Logging)?
The paper contrasts provenance mechanisms and argues that blockchain commitments provide third-party verifiability, immutable timestamps, and guaranteed detection of silent overwrites beyond typical repository or logging trust assumptions.
| Property | Git / DVC | Centralized Logging | Blockchain-backed (SlideChain) |
|---|---|---|---|
| Third-party verifiability | No | No | Yes |
| Tamper resistance | Limited (admin trust) | Limited (operator trust) | Strong (cryptographic) |
| Timestamp immutability | No | No | Yes |
| Silent overwrite detection | Partial | Partial | Guaranteed |
| Long-term auditability | Limited | Limited | Strong |
🚀 Key Contributions
- Multi-model semantic extraction pipeline producing structured concepts + triples per slide
- Unified provenance JSON schema enabling cross-model comparison and deterministic hashing
- Lightweight EVM smart contract storing only slide-level hash commitments and metadata
- First systematic stability analysis of VLM semantics on real STEM lecture slides
- Comprehensive gas/cost/throughput evaluation showing near-constant per-slide gas usage and linear scaling
- 100% tamper detection and perfect reproducibility under controlled execution settings
🎯 Research Significance
SlideChain argues that provenance must be a first-class component of educational AI: not just tracking datasets and code, but anchoring the semantic outputs produced by VLMs. By storing only compact Keccak-256 commitments on-chain and keeping full semantics off-chain, SlideChain provides strong integrity guarantees with practical scalability. The empirical results reveal substantial cross-model semantic divergence on real STEM slides and show how immutable commitments enable long-term auditing of semantic drift, reproducibility, and integrity in AI-assisted instructional pipelines.
📝 Citation
If you find SlideChain useful in your research, please consider citing:
@article{motaleb2025slidechain,
title={SlideChain: Semantic Provenance for Lecture Understanding via Blockchain Registration},
author={Motaleb Hossen Manik, Md and Zabirul Islam, Md and Wang, Ge},
journal={arXiv e-prints},
pages={arXiv--2512},
year={2025}
}
📖 Paper:
arXiv:2512.21684 (2025)
Development of an optically emulated computed tomography scanner for college education
Highlights
Conventional computed tomography (CT) systems rely on ionizing radiation, high-cost equipment, and regulatory oversight, limiting their accessibility in educational environments. We present a low-cost Optically Emulated Computed Tomography (OECT) scanner that uses visible light transmission instead of X-rays to safely demonstrate tomographic principles.
Key Achievements:
- 🔒 Radiation-Free Imaging: Uses visible light instead of ionizing radiation
- 💰 Low-Cost System: Total build cost approximately $705
- ⚙️ Modular Hardware: 3D-printed stage + Teensy microcontroller + DSLR imaging
- 📐 Tomographic Reconstruction: MATLAB-based sinogram generation + inverse Radon transform
- 📊 Spatial Resolution: Achieves ~0.1–0.2 mm resolution
- ⏱️ Scan Time: Full 360° scan in ~200 seconds
- 🧪 Validated on Lemon Slice: Successfully reconstructed peel, pulp, and seeds
🏗️ System Architecture
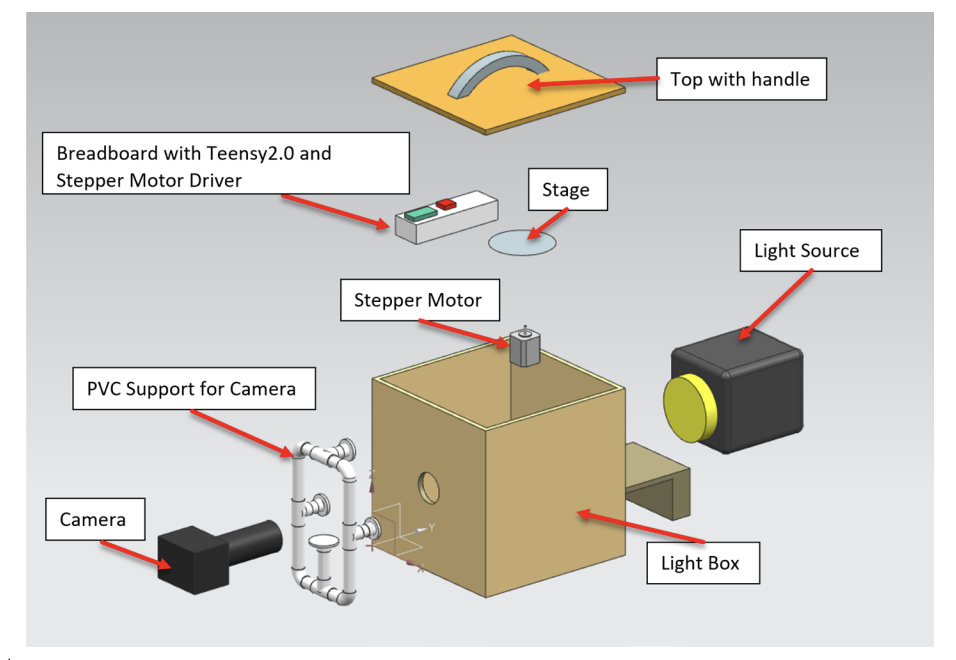
Figure 1. Design of the OECT system. The scanner integrates a light-isolated plywood enclosure, Milwaukee LED backlight, 3D-printed rotating stage, NEMA 17 stepper motor, Teensy 2.0 microcontroller, DSLR camera with 50mm prime lens, and breadboard control circuitry.
💡 Illumination & Optical Setup

Figure 2. LED light source and diffuser. A Milwaukee LED bar with diffuser ensures uniform transmission illumination. The interior of the light box is painted matte black to suppress reflections.
🔄 Rotating Stage & Camera Integration
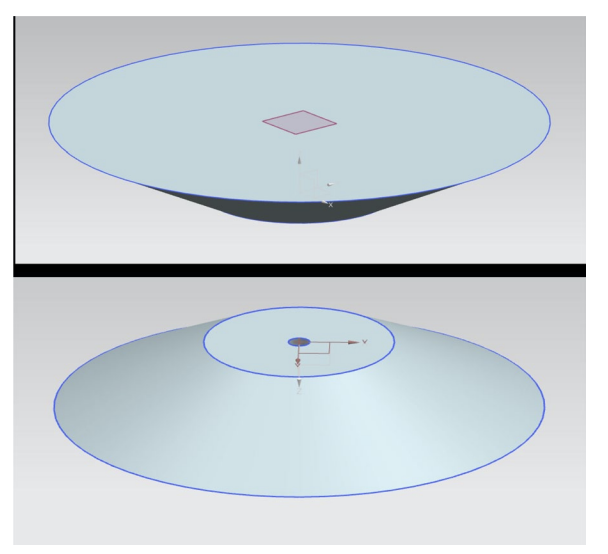
Figures 3–5. The 3D-printed PLA rotating stage is driven by a NEMA 17 stepper motor. A Nikon D5600 DSLR with 50mm f/1.8 lens is mounted via PVC stabilizers aligned precisely with the rotational axis.
⚡ Control Electronics
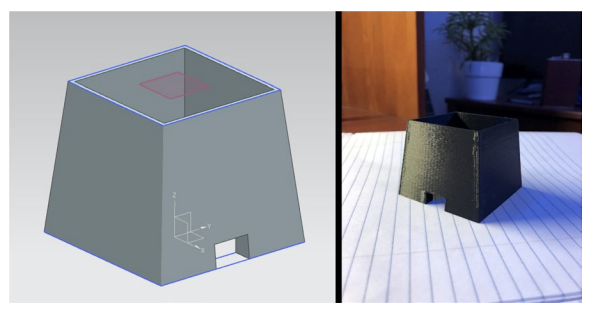
Figure 6. Breadboard circuit with Teensy 2.0 and A4988 motor driver. The microcontroller regulates angular increments while the DSLR performs interval capture.
📊 System Cost Breakdown
| Component | Cost (USD) |
|---|---|
| Nikon D5600 DSLR | $500 |
| 50mm f/1.8 Lens | $100 |
| Stepper Motor + Driver | $15 |
| Teensy 2.0 | $20 |
| LED + Diffuser | $30 |
| Miscellaneous + PLA | $40 |
| Total | $705 |
📈 Reconstruction Results

Figure 9. Sinogram generated from 200 projections. Repeating features reflect lemon symmetry.

Figure 10. Reconstructed cross-section using inverse Radon transform. Peel and seeds appear as darker regions.
🧪 Quantitative ROI Analysis
| Region | Mean Intensity (AU) |
|---|---|
| Peel | 0.99 ± 0.02 |
| Seeds | 0.71 ± 0.04 |
Intensity difference: 0.28 AU (P < 0.001), confirming contrast sensitivity.
🌐 3D Volume Rendering
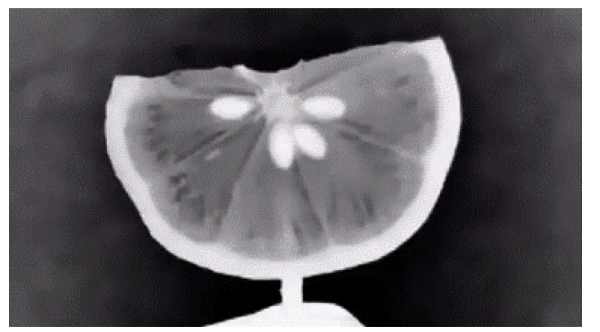
Figure 11. Volumetric rendering using Vol3D in MATLAB. Peel appears high-opacity; pulp semi-transparent; seeds clearly visible.
🎓 Educational & Technical Impact
- Radiation-free demonstration of CT principles
- Hands-on integration of optics, electronics, and reconstruction math
- Low-cost replicable design using consumer components
- Platform for STEM, digital art, and prototyping education
🔬 Research Significance
This work demonstrates that tomographic imaging principles can be effectively adapted to visible-light transmission using consumer-grade hardware. The OECT system provides a safe, reproducible, and modular platform that bridges theory and hands-on experimentation in imaging science.
📝 Citation
If you find emulated computed tomography scanner useful in your research, please consider citing:
@article{hossen2026development,
title={Development of an optically emulated computed tomography scanner for college education},
author={Hossen Manik, Md Motaleb and Muldowney, William and Islam, Md Zabirul and Wang, Ge},
journal={Visual Computing for Industry, Biomedicine, and Art},
volume={9},
number={1},
pages={2},
year={2026},
publisher={Springer}
}Avatars in the educational metaverse
Highlights
The educational metaverse promises immersive, collaborative learning, but effective learning inside virtual worlds depends on avatars that can teach, guide, and interact naturally. This review analyzes how avatars are used in metaverse-based education and how recent advances in AI (LLMs, ASR, TTS, generative models) are expanding avatar capabilities for personalized learning, contextual teaching, and simulation-based training, while also surfacing key risks in hallucinations, privacy, ethics, and infrastructure.
Key Achievements:
- 📚 Systematic + Bibliometric Review: Combined bibliometric analysis and systematic literature review methodology
- 🔎 Scopus-Driven Evidence Base: Scopus search (Nov 2024) identified 1,431 records; curated to 623 articles (1997–2024)
- 🧪 Empirical Deep Dive: Selected 45 high-quality empirical studies (Q1/Q2 venues) for content analysis
- 📈 Research Growth Trend: Annual publication trajectory shows major growth after the early 2010s, accelerating through 2017–2024
- 🧠 AI-Driven Avatar Capabilities: Reviews how LLMs + multimodal systems enable more natural instruction and feedback loops
- ⚠️ Practical Barriers Mapped: Identifies core challenges: hallucinations/trust, privacy/security, accessibility/infrastructure
- 🧭 Future Research Agenda: Outlines directions including trust modeling, emotional attachment, ethical safeguards, and scalable deployment
🏗️ Study Overview & Methodology
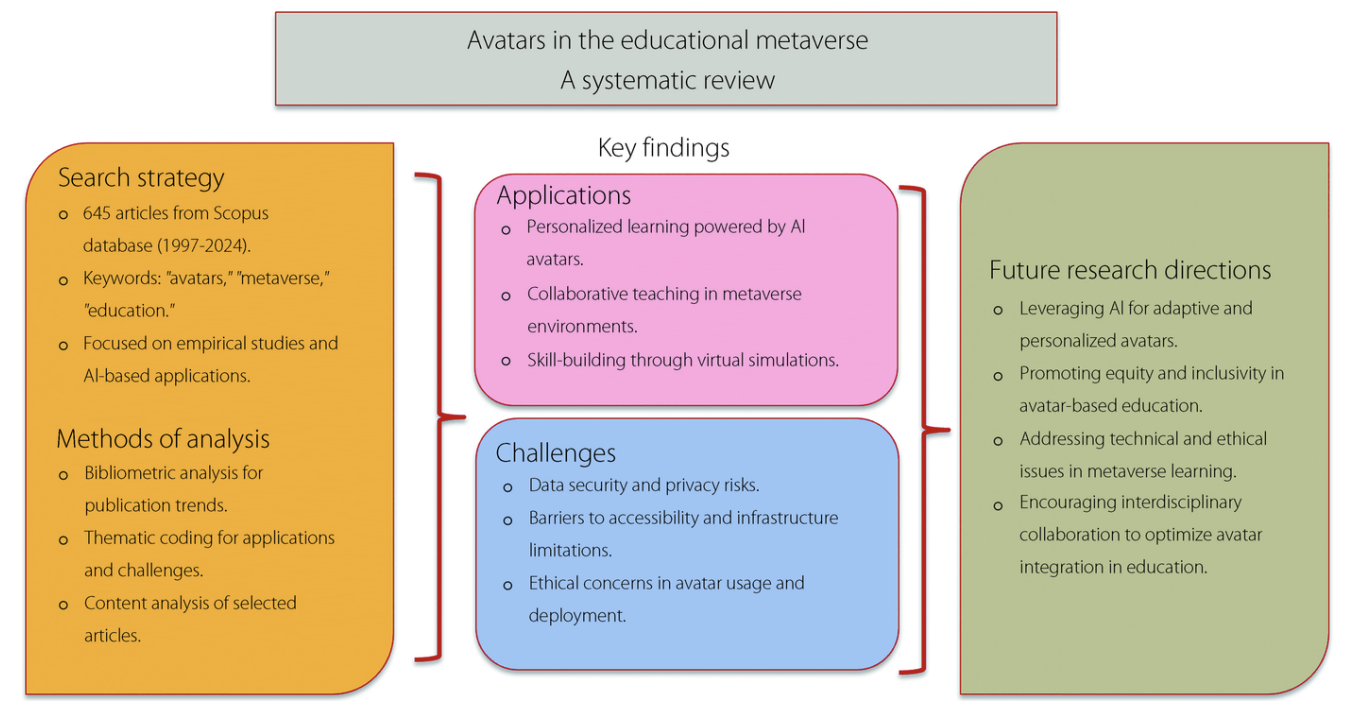
Figure 1: Graphical overview of educational metaverse (systematic review workflow). The paper uses a mixed approach: (1) Scopus keyword search and filtering, (2) bibliometric analysis to quantify trends, and (3) thematic/content coding of a curated empirical subset focusing on avatar applications in personalized learning, collaborative teaching, and virtual simulations.
The literature pipeline begins with a Scopus search (Nov 2024) over English publications containing “avatars”, “metaverse”, and “education” (title/abstract/keywords). From 1,431 initial results, manual screening and inclusion/exclusion criteria yield a final dataset of 623 articles published between 1997–2024. A refined subset of 45 empirical studies (Q1/Q2 sources, strong relevance, data-driven focus) is then analyzed in depth.
📊 Dataset Summary (Bibliometrics)
| Category | Value |
|---|---|
| Year range | 1997–2024 (Nov) |
| Total journals | 278 |
| Total articles | 623 |
| Average age of articles | 6.57 years |
| Average citations per article | 12.86 |
| Total references / citing publications | 8,010 |
Table 1 (paper): Summary statistics of the curated bibliometric dataset.
📈 Publication Growth Trend
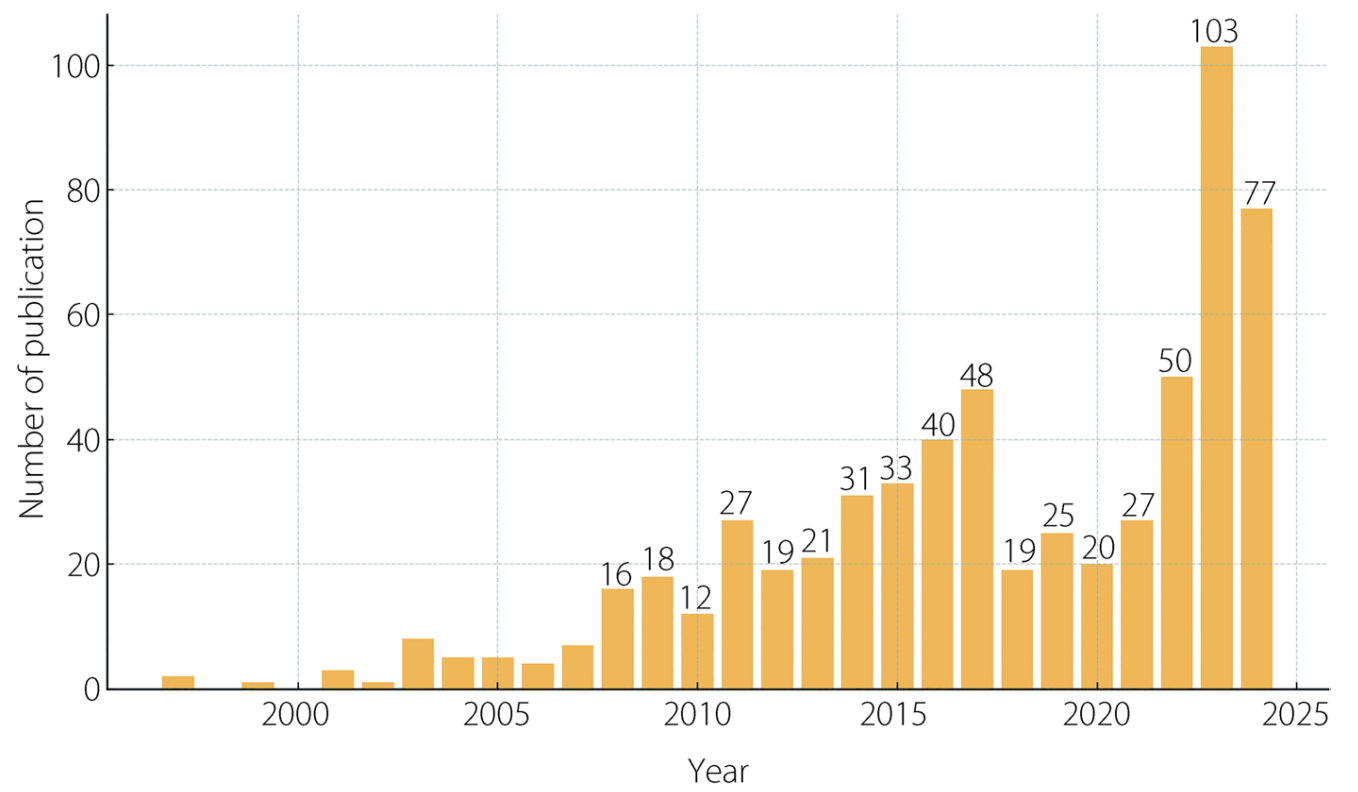
Figure 2: Annual publication trends (1997–2024). Output remains low until the early 2010s, then rises sharply, with strong acceleration in the 2017–2024 period, reflecting rapid adoption of metaverse platforms and AI-enabled avatar technologies in education research.
🧩 Content Analysis Coding Framework
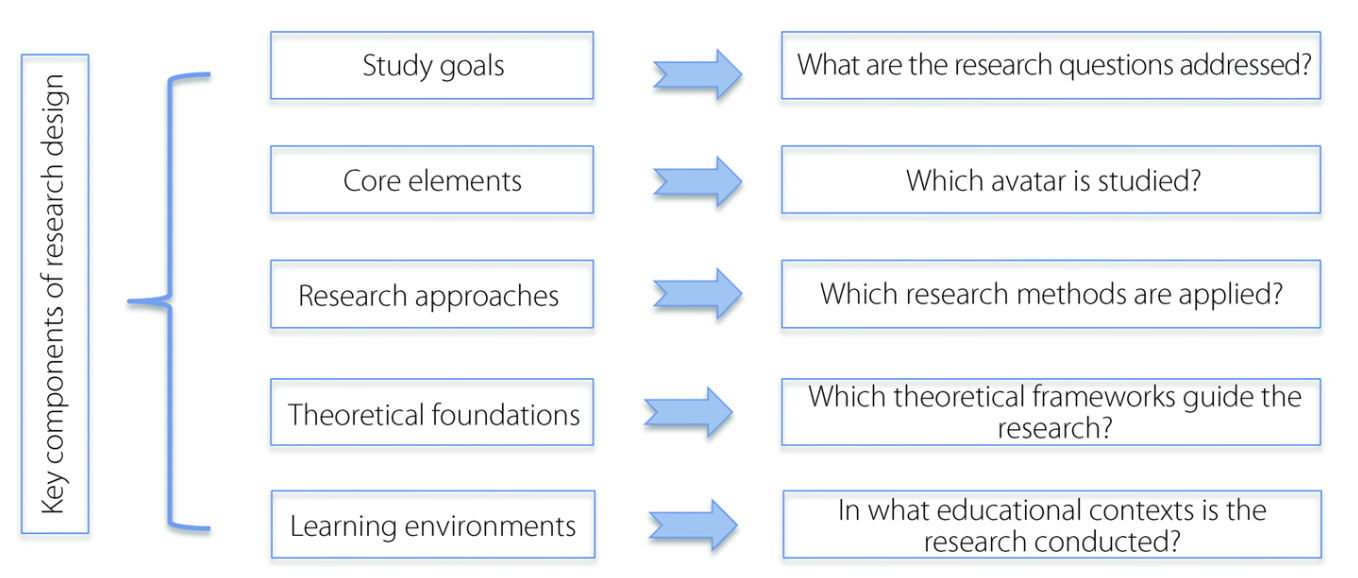
Figure 3: Coding framework for content analysis. The review codes empirical studies along dimensions such as: study goals, core elements (which avatar), research approaches (methods), theoretical foundations, and learning environments (educational context).
🧠 Key Themes: How Avatars Support Learning
The paper describes three principal educational roles for avatars: (1) supporting learning (instruction + assessment), (2) facilitating tasks (guidance and process support), and (3) mentoring (skill development and self-regulation). Across the literature, avatars are most impactful when they are adaptive, interactive, and embedded in the learner’s context.
1) Technological Advances in Avatar Design
- Speech + Dialogue Foundations: Progress in ASR and TTS makes real-time spoken interaction practical in learning agents
- LLM & Generative AI Expansion: Modern avatars increasingly use LLMs for flexible instruction, explanation, and Q&A
- Multimodal Interaction: Ability to incorporate images/video context expands tutoring beyond plain text
- Design & Comfort: Realism can improve presence, but excessive realism risks the uncanny valley effect
2) Personalized Learning
- Adaptive Difficulty & Feedback: Avatars can adjust content based on learner performance and interaction signals
- Language Learning: Real-time conversation practice using ASR/TTS is a common effective use case
- Engagement Mechanisms: Facial expression, culturally appropriate appearance, and interactive pacing support motivation
3) Contextualized Teaching
- Role-Play & Case-Based Learning: Avatars enable simulations that are difficult/costly in physical settings (e.g., medical training)
- Teacher Training: Classroom simulation supports practicing strategies, managing behaviors, and improving confidence
- Real-time Responsiveness: NLP-driven avatars can react dynamically to learner decisions and questions
4) Virtual Learning in VR/AR/MR
- Navigational Support: Avatars guide learners through complex virtual spaces, reducing cognitive load
- Generative Learning Prompts: Avatars can prompt concept mapping, explanation, and “teach-back” behaviors to improve retention
- Collaboration: Metaverse environments support group interaction, teamwork, and communication skill development
⚠️ Challenges & Ethical Considerations
1) Hallucinations & Trust
A core risk is that LLM-driven avatars may generate plausible but incorrect information (“hallucinations”). The paper emphasizes that photorealistic avatars and human-like delivery can amplify perceived credibility, increasing the chance that learners accept incorrect content as true.
2) Data Security & Privacy
Educational avatars often process sensitive learner information (performance, goals, emotional state). The paper notes risks from cloud-based pipelines across jurisdictions, voice/image misuse (deepfake threats), and the need for careful handling of personal data to maintain confidentiality and trust.
3) Accessibility & Infrastructure
Immersive metaverse learning requires high-speed networking, low latency, capable hardware, and technical expertise. The paper highlights that cost and technical requirements can limit adoption in resource-constrained institutions and regions.
🧭 Future Research Directions
- Trust & Long-term Attachment: How learners build trust and emotional connection with avatars over extended periods
- Ethical Safeguards: Stronger guidance for use with children/vulnerable groups, plus bias and misinformation mitigation
- Hallucination Controls: Mechanisms to detect and reduce inaccurate content in avatar-delivered explanations
- Data + Digital Twins: Integrating real-world signals (IoT, simulations) into meaningful, context-aware learning loops
- Scalable Access: Lower-cost, lightweight avatar systems that work under limited bandwidth and modest hardware
🎓 Educational & Practical Impact
- Improved Engagement: Avatars increase presence and interaction in immersive learning spaces
- Personalized Support: Adaptive tutoring and real-time feedback in language, STEM, and professional training
- Safe Simulation: Cost-effective practice for scenarios that are expensive, risky, or hard to stage physically
- Clear Deployment Warnings: Strong emphasis on privacy, hallucination risk, and equitable access requirements
🔬 Research Significance
This review consolidates the evidence that avatars can meaningfully enhance metaverse-based education through adaptive, interactive learning support, contextual simulations, and collaborative virtual environments. At the same time, it clarifies why responsible deployment requires explicit safeguards against hallucinations, robust privacy and security practices, and practical solutions for infrastructure and accessibility barriers.
📝 Citation
If you find Avatars in the educational metaverse useful in your research, please consider citing:
@article{islam2025avatars,
title={Avatars in the educational metaverse},
author={Islam, Md Zabirul and Wang, Ge},
journal={Visual Computing for Industry, Biomedicine, and Art},
volume={8},
number={1},
pages={15},
year={2025},
publisher={Springer}
}